This Wednesday (27th March) Mat Keep and I will be presenting a free, live webinar on MySQL 5.6 Replication. You need to register here ahead of the webinar – worth doing even if you can’t attend as you’ll then be sent a link to the replay when it’s available. We’ll also have some of the key MySQL replication developers on-line to answer your questions and so it’s also a great chance to get some free consultancy 😉
Details….
Join this session to learn how the new replication features in MySQL 5.6 enable developers and DBAs to build and scale next generation services using the world’s most popular open source database. MySQL 5.6 delivers new replication capabilities which we will discuss and demonstrate in the webinar:
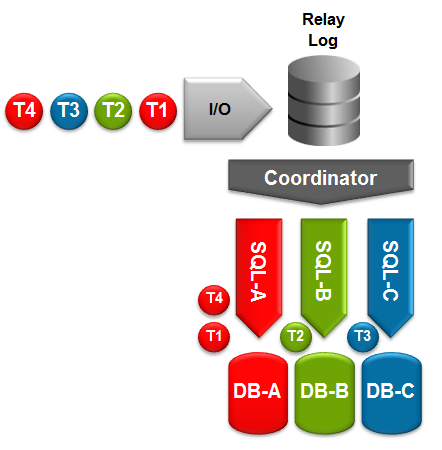
High performance with Binary Log Group Commit, Multi-Threaded Slaves and Optimized Row Based Replication
High availability with Global Transaction Identifiers, Failover Utilities and Crash Safe Slaves & Binlog
Data integrity with Replication Event Checksums
Dev/Ops agility with new Replication Utilities, Time Delayed Replication and more
The session will wrap up with resources to get started with MySQL 5.6.
WHEN:
Wed, Mar 27: 07:00 Pacific time (America)
Wed, Mar 27: 08:00 Mountain time (America)
Wed, Mar 27: 09:00 Central time (America)
Wed, Mar 27: 10:00 Eastern time (America)
Wed, Mar 27: 14:00 UTC
Wed, Mar 27: 14:00 Western European time
Wed, Mar 27: 15:00 Central European time
Wed, Mar 27: 16:00 Eastern European time
Wed, Mar 27: 19:30 India, Sri Lanka
Wed, Mar 27: 22:00 Singapore/Malaysia/Philippines time
Wed, Mar 27: 22:00 China time
Wed, Mar 27: 23:00 日本
Thu, Mar 28: 01:00 NSW, ACT, Victoria, Tasmania (Australia)
The presentation will be approximately 60 minutes long.
MySQL 5.6 has now been declared Generally Available (i.e. suitable for production use). This is a very exciting release from a MySQL replication perspective with some big new features. These include:
Global Transaction Identifiers (GTIDs) – a unique identifier that is used accross your replication topology to identify a transaction. Makes setting up and managing your cluster (including the promotion of a new master) far simpler and more reliable.
Multi-threaded slaves (MTS) – Increases the performance of replication on the slave; different threads will handle applying events to different databases.
Binary Log Group Commit – Improves replication performance on the master.
Optimized Row Based Replication – reduces the amount of data that needs to be replicated; reducing network usage and potentially speeding up replication.
Crash-Safe Replication – makes replication transactional. The data and replication positioning information are both updated as part of the same transaction.
Replication Event Checksums – checks to ensure that the data being replicated hasn’t become corrupted, avoids writing corrupted data to the slave.
Time-Delayed Replication – configure one or more of your slaves to only apply replicated events after a configured time. This can be useful to protect against DBA mistakes.
Informational Logs – includes the original statement in the binary log when using row-based-replication to aid in debugging.
If you’re already familiar with using MySQL Replication, here are a few pointers on what to do differently for the new MySQL 5.6 features but you should refer to the full tutorial to see these changes in context.
First of all, here are some extra configuration parameters to include…
When initiating (or restarting) replication on the slave, it is no longer necessary to include the binary log positioning information as the master and slave will automatically negotiate what outstanding events need to be replicated based on any GTIDs previously received by the slave…
slave> CHANGE MASTER TO MASTER_HOST='black',
MASTER_USER='repl_user',
MASTER_PASSWORD='billy',
MASTER_AUTO_POSITION=1;
Please try out these new features and let us know what you think.
The Free and Open source Software Developers’ European Meeting (FOSDEM) is a two-day event organized by volunteers to promote the widespread use of Free and Open Source software.
I attended for the first time over the weekend and was really impressed by the number of people there, the energy and the quality of the content. The event really lives up to it’s name and is very developer-focused.
In the end, I got the opportunity to make 2 presentations. The first is a general introduction to MySQL Cluster….
The second illustrates how you can realise the benefits promised by NoSQL data stores wihtout losing the consistency and flexibility of relational databases…
The Free and Open source Software Developers’ European Meeting (FOSDEM) is a two-day event organized by volunteers to promote the widespread use of Free and Open Source software. As in previous years, there is a dedicated stream of MySQL Sessions. On Saturday (2nd Feb) evening there’s a MySQL community dinner and then we’ve a packed program from 9:15 through 17:30 on Sunday (3rd Feb).
FOSDEM 2013 is a free event and there’s no requirement to pre-register – just get yourself along to Brussels.
This year I’ll be making a presentation introducing MySQL Cluster. Several of my colleagues from Oracle will also be there to present on the latest and greatest MySQL capabilities – including what’s coming in MySQL 5.6. This will be a great opportunity to politely listen to some real technical experts but an even better one to pester them for extra details – whether during the presentations or when you can grab them at other times.
Oracle have just announced that MySQL Cluster Manager 1.2 is Generally Available. For anyone not familiar with MySQL Cluster Manager – it’s a command-line management tool that makes it simpler and safer to manage your MySQL Cluster deployment – use it to create, configure, start, stop, upgrade…. your cluster.
So what has changed since MCM 1.1 was released?
The first thing is that a lot of work has happened under the covers and it’s now faster, more robust and can manage larger clusters. Feature-wise you get the following (note that a couple of these were released early as part of post-GA versions of MCM 1.1):
Automation of on-line backup and restore
Single command to start MCM and a single-host Cluster
Multiple clusters per site
Single command to stop all of the MCM agents in a Cluster
Provide more details in “show status” command
Ability to restart “initial” the data nodes in order to wipe out the database ahead of a restore
A new version of the MySQL Cluster Manager white paper has been released that explains everything that you can do with it and also includes a tutorial for the key features; you can download it here.
Watch this video for a tutorial on using MySQL Cluster Manager, including the new features:
Using the new features
Single command to run MCM and then create and run a Cluster
A single-host cluster can very easily be created and run – an easy way to start experimenting with MySQL Cluster:
billy@black:~$ mcm/bin/mcmd –bootstrap
MySQL Cluster Manager 1.2.1 started
Connect to MySQL Cluster Manager by running "/home/billy/mcm-1.2.1-cluster-7.2.9_32-linux-rhel5-x86/bin/mcm" -a black.localdomain:1862
Configuring default cluster 'mycluster'...
Starting default cluster 'mycluster'...
Cluster 'mycluster' started successfully
ndb_mgmd black.localdomain:1186
ndbd black.localdomain
ndbd black.localdomain
mysqld black.localdomain:3306
mysqld black.localdomain:3307
ndbapi *
Connect to the database by running "/home/billy/mcm-1.2.1-cluster-7.2.9_32-linux-rhel5-x86/cluster/bin/mysql" -h black.localdomain -P 3306 -u root
You can then connect to MCM:
billy@black:~$ mcm/bin/mcm
Or access the database itself simply by running the regular mysql client.
Extra status information
When querying the status of the processes in a Cluster, you’re now also shown the package being used for each node:
You may then select which of these backups you want to restore by specifying the associated BackupId when invoking the restore command:
mcm> restore cluster -I 1 mycluster;
Note that if you need to empty the database of its existing contents before performing the restore then MCM 1.2 introduces the initial option to the start cluster command which will delete all data from all MySQL Cluster tables.
Stopping all MCM agents for a site
A single command will now stop all of the agents for your site:
Oracle has announced that it now provides support for DRBD with MySQL – this means a single point of support for the entire MySQL/DRBD/Pacemaker/Corosync/Linux stack! As part of this, we’ve released a new white paper which steps you through everything you need to do to configure this High Availability stack. The white paper provides a step-by-step guide to installing, configuring, provisioning and testing the complete MySQL and DRBD stack, including:
MySQL Database
DRBD kernel module and userland utilities
Pacemaker and Corosync cluster messaging and management processes
Oracle Linux operating system
DRBD is an extremely popular way of adding a layer of High Availability to a MySQL deployment – especially when the 99.999% availability levels delivered by MySQL Cluster isn’t needed. It can be implemented without the shared storage required for typical clustering solutions (not required by MySQL Cluster either) and so it can be a very cost effective solution for Linux environments.
Introduction to MySQL on DRBD/Pacemaker/Corosync/Oracle Linux
Fig 1 – MySQL-DRBD Stack
Figure 1 illustrates the stack that can be used to deliver a level of High Availability for the MySQL service.
At the lowest level, 2 hosts are required in order to provide physical redundancy; if using a virtual environment, those 2 hosts should be on different physical machines. It is an important feature that no shared storage is required. At any point in time, the services will be active on one host and in standby mode on the other.
Pacemaker and Corosync combine to provide the clustering layer that sits between the services and the underlying hosts and operating systems. Pacemaker is responsible for starting and stopping services – ensuring that they’re running on exactly one host, delivering high availability and avoiding data corruption. Corosync provides the underlying messaging infrastructure between the nodes that enables Pacemaker to do its job; it also handles the nodes membership within the cluster and informs Pacemaker of any changes.
The core Pacemaker process does not have built in knowledge of the specific services to be managed; instead agents are used which provide a wrapper for the service-specific actions. For example, in this solution we use agents for Virtual IP Addresses, MySQL and DRBD – these are all existing agents and come packaged with Pacemaker. This white paper will demonstrate how to configure Pacemaker to use these agents to provide a High Availability stack for MySQL.
The essential services managed by Pacemaker in this configuration are DRBD, MySQL and the Virtual IP Address that applications use to connect to the active MySQL service.
DRBD synchronizes data at the block device (typically a spinning or solid state disk) – transparent to the application, database and even the file system. DRBD requires the use of a journaling file system such as ext3 or ext4. For this solution it acts in an active-standby mode – this means that at any point in time the directories being managed by DRBD are accessible for reads and writes on exactly one of the two hosts and inaccessible (even for reads) on the other. Any changes made on the active host are synchronously replicated to the standby host by DRBD.
Setting up MySQL with DRBD/Pacemaker/Corosync/Oracle Linux
Fig 2 – Target network config
Figure 2 shows the network configuration used in this paper – note that for simplicity a single network connection is used but for maximum availability in a production environment you should consider redundant network connections.
A single Virtual IP (VIP) is shown in the figure (192.168.5.102) and this is the address that the application will connect to when accessing the MySQL database. Pacemaker will be responsible for migrating this between the 2 physical IP addresses.
One of the final steps in configuring Pacemaker is to add network connectivity monitoring in order to attempt to have an isolated host stop its MySQL service to avoid a “split-brain” scenario. This is achieved by having each host ping an external (not one part of the cluster) IP addresses – in this case the network router (192.168.5.1).
Fig 3 – Locations of files
Figure 3 shows where the MySQL files will be stored. The MySQL binaries as well as the socket (mysql.sock) and process-id (mysql.pid) files are stored in a regular partition – independent on each host (under /var/lib/mysql/). The MySQL Server configuration file (my.cnf) and the database files (data/*) are stored in a DRBD controlled file system that at any point in time is only available on one of the two hosts – this file system is controlled by DRBD and mounted under /var/lib/mysql_drbd/.
Fig 4 – Clustered resources
The white paper steps through setting all of this up as well as the resources in Pacemaker/Corosync that allow detection of a problem and the failover of the storage (DRBD), database (MySQL) and the Virtual IP address used by the application to access the database – all in a coordinated way of course. As you’ll notice in Figure 4 this involves setting up quite a few entities and relationships – the paper goes through each one.
Deploying a well configured cluster has just got a lot easier! Oracle have released a new auto-installer/configurator for MySQL Cluster that makes the processes extremely simple while making sure that the cluster is well configured for your application. The installer is part of MySQL Cluster 7.3 and so is not yet GA but it can also be used on MySQL Cluster 7.2. A single command launches the web-based wizard which then steps you through configuring the cluster; to keep things even simpler, it will automatically detect the resources on your target machines and use these results together with the type of workload you specify in order to determine values for the key configuration parameters.
Tutorial Video
Before going through the detailed steps, here’s a demonstration of the auto-installer in action…
Downloading and running the wizard
The software can be downloaded from MySQL Labs; just select the MySQL-Cluster-Auto-Installer build, unzip the file and then run. To run on Windows, just double click setup.bat – note that if you installed from the MSI and didn’t change the install directory then this will be located somewhere like C:Program Files (x86)MySQLMySQL Cluster 7.2. On Linux, just run ndb_setup.
Creating your cluster
Landing page
When you run the auto-installer it starts a small web server and then (if possible) automatically connects your web browser to it – presenting you with the first page of the wizard. If this isn’t possible (for example the server isn’t running a desktop environment), then you can connect to it remotely using the URL http://your-server-name-goes-here:8081/index.html. It may take a number of seconds to load and so please be patient. Note that the machine where you run this doesn’t need to be a host that will be included in the cluster.
From the landing page, just click on the “Create new MySQL Cluster” icon to get started.
On the next page you need to specify the list of servers that will form part of the cluster. The machine where the installer is being run from needs to have ssh access to all of the cluster hosts (further, access to those machines must already have been approved from this one – if you’re uncertain, just manually connect to each one using an ssh client.
By default, the wizard assumes that ssh keys have been set up (so that a password isn’t needed) – if that isn’t the case, just un-check the checkbox and provide your username and password.
On this page, you also get to specify what “type” of cluster you want; if you’re experimenting for the first time then it’s probably safest to stick with “Simple testing” but for a production system you’d want to specify the kind of application and whether it will a write-intensive application.
Auto-discovery of target host resources
On the next page, you will see the wizard attempt to auto-detect the resources on your target machines. If this fails then you can enter the data manually.
You can also overwrite the resource-values (for example, if you don’t want the cluster to use up a big share of the memory on the target systems then just overwrite the amount of memory.
Overwriting the default directories on the target systems
It’s also on this page that you can specify where the MySQL Cluster software is stored on each of the hosts (if the defaults aren’t correct) – this should be the path to where you unzipped the MySQL Cluster tar-ball/zip file – as well as where the data (and configuration files) should be stored. You can just overwrite the values or select multiple rows and hit the “edit” button.
Defining processes
The following page presents you with a default set of nodes (processes) and how they’ll be distributed across all of the target hosts – if you’re happy with the proposal then just advance to the next page. So what can you change:
Add extra nodes
Move nodes from one host to another (just drag and drop)
Delete nodes
Change a node from one type to another
Add process
The diagram to the right shows an example of adding an extra MySQL Server.
On the next screen you’re presented with some of the key configuration parameters that have been set (behind the scenes, the wizard sets many more) that you might want to override; if you’re happy then just progress to the next screen. If you do want to make any changes then make them here before continuing. If you’d previously selected anything other than “simple” for the kind of cluster to create then you can check the “Show advanced configuration options” box in order to view/modify more parameters.
Deployment in progress
On the final screen you can review the details of the final recommended configuration and then just hit “Deploy and start cluster” and it will do just that. Depending on the complexity of the cluster, it can take a while to deploy and start everything but you’re shown a progress bar together with an explanation of what stage the process is at.
If for some reason you prefer or need to start the processes manually, this page also shows you the commands that you’d need to run (as well as the configuration files if you need to create them manually).
Once the wizard declares the process complete, you can check for yourself before going ahead and start your testing: