Data Streaming
In today’s data landscape, no single system can provide all of the required perspectives to deliver real insight. Deriving the full meaning from data requires mixing huge volumes of information from many sources.
At the same time, we’re impatient to get answers instantly; if the time to insight exceeds 10s of milliseconds then the value is lost – applications such as high frequency trading, fraud detection, and recommendation engines can’t afford to wait. This often means analyzing the inflow of data before it even makes it to the database of record. Add in zero tolerance for data loss and the challenge gets even more daunting.
Kafka and data streams are focused on ingesting the massive flow of data from multiple fire-hoses and then routing it to the systems that need it – filtering, aggregating, and analyzing en-route.
This blog introduces Apache Kafka and then illustrates how to use MongoDB as a source (producer) and destination (consumer) for the streamed data. A more complete study of this topic can be found in the Data Streaming with Kafka & MongoDB white paper.
Apache Kafka
Kafka provides a flexible, scalable, and reliable method to communicate streams of event data from one or more producers to one or more consumers. Examples of events include:
- A periodic sensor reading such as the current temperature
- A user adding an item to the shopping cart in an online store
- A Tweet being sent with a specific hashtag
Streams of Kafka events are organized into topics. A producer chooses a topic to send a given event to, and consumers select which topics they pull events from. For example, a financial application could pull NYSE stock trades from one topic, and company financial announcements from another in order to look for trading opportunities.
In Kafka, topics are further divided into partitions to support scale out. Each Kafka node (broker) is responsible for receiving, storing, and passing on all of the events from one or more partitions for a given topic. In this way, the processing and storage for a topic can be linearly scaled across many brokers. Similarly, an application may scale out by using many consumers for a given topic, with each pulling events from a discrete set of partitions.
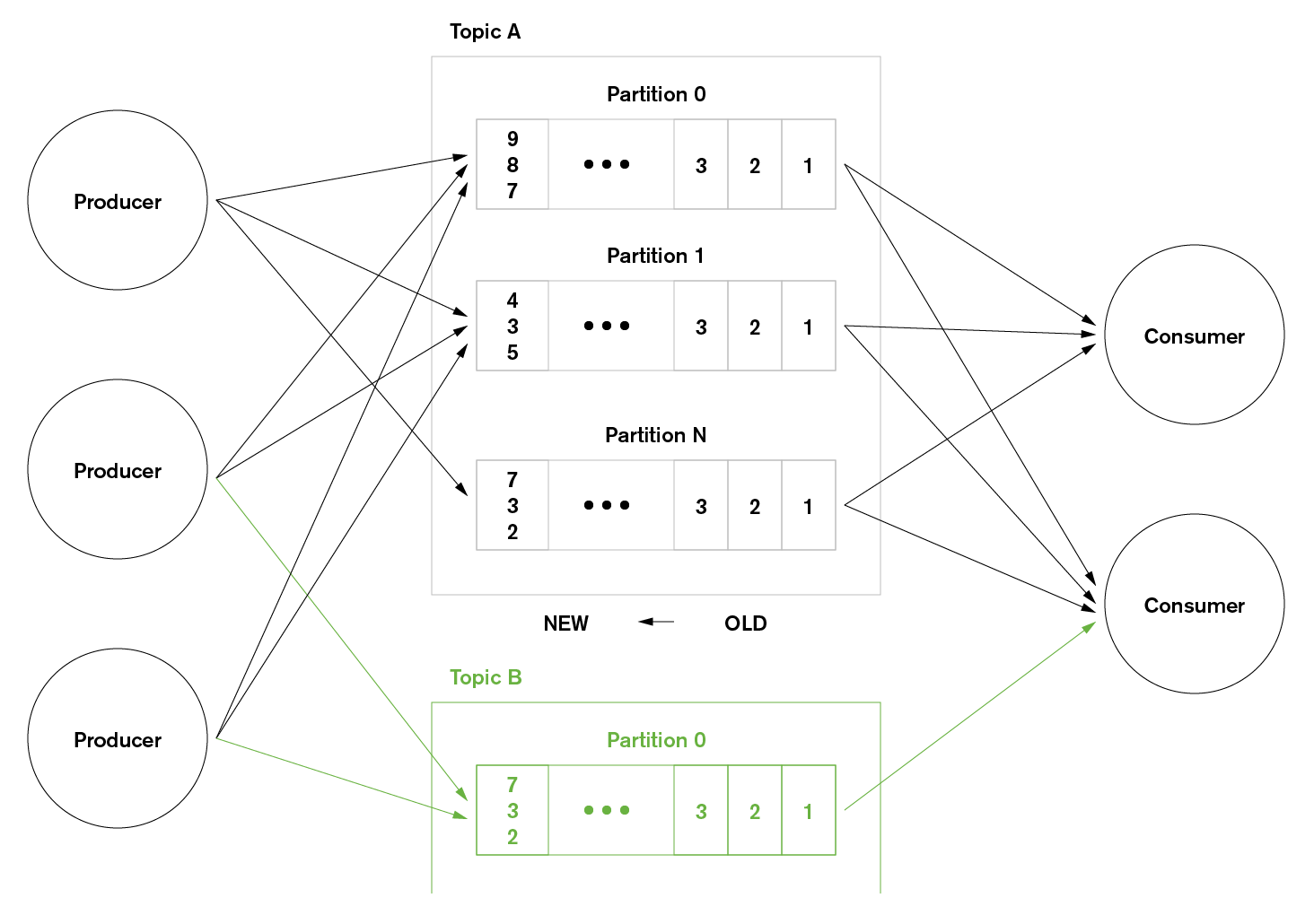
Figure 1: Kafka Producers, Consumers, Topics, and Partitions
MongoDB As A Kafka Consumer – A Java Example
In order to use MongoDB as a Kafka consumer, the received events must be converted into BSON documents before they are stored in the database. In this example, the events are strings representing JSON documents. The strings are converted to Java objects so that they are easy for Java developers to work with; those objects are then transformed into BSON documents.
Complete source code, Maven configuration, and test data can be found further down, but here are some of the highlights; starting with the main loop for receiving and processing event messages from the Kafka topic:
The Fish class includes helper methods to hide how the objects are converted into BSON documents:
In a real application more would be done with the received messages – they could be combined with reference data read from MongoDB, acted on and then passed along the pipeline by publishing to additional topics. In this example, the final step is to confirm from the mongo shell that the data has been added to the database:
Full Java Code for MongoDB Kafka Consumer
Business Object – Fish.java
Kafka Consumer for MongoDB – MongoDBSimpleConsumer.java
Note that this example consumer is written using the Kafka Simple Consumer API – there is also a Kafka High Level Consumer API which hides much of the complexity – including managing the offsets. The Simple API provides more control to the application but at the cost of writing extra code.
Maven Dependencies – pom.xml
Test Data – Fish.json
A sample of the test data injected into Kafka is shown below:
For simple testing, this data can be injected into the clusterdb-topic1 topic using the kafka-console-producer.sh command.
Next Steps
To learn much more about data streaming and how MongoDB fits in (including Apache Kafka and competing and complementary technologies) read the Data Streaming with Kafka & MongoDB white paper and watch the webinar replay.