Language-Specific Views in MongoDB 3.4
Introduction
This post shows you how to create multiple language-specific views on top of a common collection. Each view is optimized for its language with a collated index which only presents entries for documents in that language. Additionally, each view excludes some fields from the underlying collection – further limiting the data that can be seen through the that view. Finally, user-defined roles are created to restrict users to just the view(s) they should be able to see, ensuring they can only access the data that they’re entitled to.
In the course of setting up this environment, a number of features are demonstrated:
- Read-Only Views (New in MongoDB 3.4): DBAs can define non-materialized views that expose only a subset of data from an underlying collection, i.e. a view that filters out entire documents or specific fields, such as Personally Identifiable Information (PII) from sales data or health records. As a result, risks of data exposure are dramatically reduced. DBAs can define a view of a collection that’s generated from an aggregation over another collection(s) or view.
- Multiple Language Collations (New in MongoDB 3.4): Applications addressing global audiences require handling content that spans many languages. Each language has different rules governing the comparison and sorting of data. MongoDB collations allow users to build applications that adhere to these language-specific comparison rules for over 100 different languages and locales. Developers can specify collations for collections, indexes, views, or for individual operations.
- Partial Indexes: Partial indexes balance delivering good query performance while consuming fewer system resources. For example, consider an order processing application. The
ordercollection is frequently queried by the application to display all incomplete orders for a particular user. Building an index on the userID field of the collection is necessary for good performance. However, only a small percentage of orders are in progress at a given time. Limiting the index onuserIDto contain only orders that are in the “active” state could reduce the number of index entries from millions to thousands, saving working set memory and disk space, while speeding up queries even further as smaller indexes result in faster searches. - User Defined Roles: User-defined roles, enable administrators to assign finely-grained privileges to users and applications, based on the specific functionality they require. MongoDB provides the ability to specify user privileges at both the database, collection, and view levels.
- MongoDB Compass: MongoDB Compass is the easiest way for DBAs to explore and manage MongoDB data. As the GUI for MongoDB, Compass enables users to visually explore their data, and run ad-hoc queries in seconds – all with zero knowledge of MongoDB’s query language. The latest Compass release expands functionality to allow users to manipulate documents directly from the GUI, optimize performance, and create data governance controls.
The Data Set
The example used in this post is built on a collection containing documents for customers from multiple countries – one of the fields indicates a customer’s country, but there is no field that identifies their spoken language. To fix that, we infer their language from their country to create a new language field in each document:
db.customers.updateMany(
{country: "China"},
{$set: {language: "Chinese"}})
db.customers.updateMany(
{country: "Germany"},
{$set: {language: "German"}})
db.customers.updateMany(
{country: {$in: ["USA", "Canada", "United Kingdom"]}},
{$set: {language: "English"}})
A typical document now looks like this:
db.customers.findOne()
{
"_id" : ObjectId("57fb8fbb99b01440193088eb"),
"first_name" : "Ben",
"last_name" : "Dixon",
"country" : "Germany",
"avatar" : "https://robohash.org/quiseumquam.bmp?size=50x50&set=set1",
"ip_address" : "10.102.15.35",
"dependents" : [
{
"name" : "Ben",
"birthday" : "12-Apr-1994"
},
{
"name" : "Lucas",
"birthday" : "22-Jun-2016"
},
{
"name" : "Erik",
"birthday" : "05-Jul-2005"
}
],
"birthday" : "02-Jul-1964",
"salary" : "£910070.80",
"skills" : [
{
"skill" : "Cvent"
},
{
"skill" : "TKI"
}
],
"gender" : "Male",
"language" : "German"
}
You might ask why we need to add this extra field rather than simply calculating the language each time it’s needed? The answer is that multiple countries share the same language and partial indexes don’t allow us to use the $or or $in operators.
At this stage, the only index on the collection is on the _id field:
db.customers.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "production.customers"
}
]
If you want to work through this example for yourself then the following steps will populate a collection called “customers” in a database called production:
curl -o customers.tgz http://clusterdb.com/upload/customers.tgz
tar fxz customers.tgz
mongorestore
There should be 111,000 documents in the collection after running mongorestore:
use production
db.customers.findOne()
{
"_id" : ObjectId("57fb8fbb99b01440193088eb"),
"first_name" : "Ben",
"last_name" : "Dixon",
"country" : "Germany",
"avatar" : "https://robohash.org/quiseumquam.bmp?size=50x50&set=set1",
"ip_address" : "10.102.15.35",
"dependents" : [
{
"name" : "Ben",
"birthday" : "12-Apr-1994"
},
{
"name" : "Lucas",
"birthday" : "22-Jun-2016"
},
{
"name" : "Erik",
"birthday" : "05-Jul-2005"
}
],
"birthday" : "02-Jul-1964",
"salary" : "£910070.80",
"skills" : [
{
"skill" : "Cvent"
},
{
"skill" : "TKI"
}
],
"gender" : "Male",
"language" : "German"
}
db.customers.count()
111000
Adding Indexes
Collations – allow values to be compared and sorted using rules specific to a local language. In this example, we are supporting 3 languages: English, German, and Chinese. For each of these languages, a collated index will later be used to correctly sort the customers based on their last and first name.
To this end, collation-specific, compound (last_name + first_name) indexes are created:
db.customers.createIndex(
{last_name: 1, first_name : 1 },
{name: "chinese_name_index",
collation: {locale: "zh" },
partialFilterExpression: { language: "Chinese" }
}
);
db.customers.createIndex(
{last_name: 1, first_name : 1 },
{name: "english_name_index",
collation: {locale: "en" },
partialFilterExpression: { language: "English" }
}
);
db.customers.createIndex(
{last_name: 1, first_name : 1 },
{name: "german_name_index",
collation: {locale: "de" },
partialFilterExpression: { language: "German" }
}
);
The exact behaviour of comparisons and sorting using the collated index can be further refined by including additional parameters alongside the locale in the collation documentation. Details of these optional parameters can be found in the collation documentation.
Note that each of those indexes is partial, only containing entries for document where language is set to the matching value. This saves memory and disk space, and speeds up both reads and writes.
This is the final set of indexes:
db.customers.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "production.customers"
},
{
"v" : 2,
"key" : {
"last_name" : 1,
"first_name" : 1
},
"name" : "german_name_index",
"ns" : "production.customers",
"partialFilterExpression" : {
"language" : "German"
},
"collation" : {
"locale" : "de",
"caseLevel" : false,
"caseFirst" : "off",
"strength" : 3,
"numericOrdering" : false,
"alternate" : "non-ignorable",
"maxVariable" : "punct",
"normalization" : false,
"backwards" : false,
"version" : "57.1"
}
},
{
"v" : 2,
"key" : {
"last_name" : 1,
"first_name" : 1
},
"name" : "chinese_name_index",
"ns" : "production.customers",
"partialFilterExpression" : {
"language" : "Chinese"
},
"collation" : {
"locale" : "zh",
"caseLevel" : false,
"caseFirst" : "off",
"strength" : 3,
"numericOrdering" : false,
"alternate" : "non-ignorable",
"maxVariable" : "punct",
"normalization" : false,
"backwards" : false,
"version" : "57.1"
}
},
{
"v" : 2,
"key" : {
"last_name" : 1,
"first_name" : 1
},
"name" : "english_name_index",
"ns" : "production.customers",
"partialFilterExpression" : {
"language" : "English"
},
"collation" : {
"locale" : "en",
"caseLevel" : false,
"caseFirst" : "off",
"strength" : 3,
"numericOrdering" : false,
"alternate" : "non-ignorable",
"maxVariable" : "punct",
"normalization" : false,
"backwards" : false,
"version" : "57.1"
}
}
]
Create Views
A view is created for each language to:
- Filter out any documents where the
languagefield doesn’t match that of the view - Remove the
salary,country, andlanguagefields - Indicate which collation should be used
db.createView(
"chineseSpeakersRedacted",
"customers",
[
{$match: {
language: "Chinese",
last_name: {$exists: true}
}},
{$project: {
salary: 0,
country: 0,
language: 0
}
}
],
{collation: {locale: "zh"}}
)
db.createView(
"englishSpeakersRedacted",
"customers",
[
{$match: {
language: "English",
last_name: {$exists: true}
}},
{$project: {
salary: 0,
country: 0,
language: 0
}
}
],
{collation: {locale: "en"}}
)
db.createView(
"germanSpeakersRedacted",
"customers",
[
{$match: {
language: "German",
last_name: {$exists: true}
}},
{$project: {
salary: 0,
country: 0,
language: 0
}
}
],
{collation: {locale: "de"}}
)
You might ask why last_name: {$exists: true} is included in the $match stage? The reason is that it encourages the optimizer to use our language-specific partial indexes when using these views.
Note that this is using the MongoDB Aggregation Framework and so you could add lots of other operations, including: unwinding arrays, looking up values from other collections, grouping data, and adding new, computed fields.
The views now appear like collections and can be queried in the same manner (note that they are ready-only):
show collections
chineseSpeakersRedacted
customers
englishSpeakersRedacted
germanSpeakersRedacted
system.views
db.germanSpeakersRedacted.find({last_name: "Cole"}, {first_name:1, _id:0, gender:1}).sort({first_name: 1})
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Amelie", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anna", "gender" : "Female" }
{ "first_name" : "Anton", "gender" : "Male" }
{ "first_name" : "Anton", "gender" : "Male" }
{ "first_name" : "Anton", "gender" : "Male" }
The query above searches for all documents where the last_name is Cole (because this query is using the German view, behind the scenes, all non-German documents have already been filtered out), discards all but the first_name and gender fields, and then sorts by the first_name (using the German collation).
explain() confirms that the German collation index was used:
db.germanSpeakersRedacted.find({last_name: "Cole"}, {first_name:1, _id:0, gender:1}).sort({first_name: 1}).explain()
{
"stages" : [
{
"$cursor" : {
"query" : {
"$and" : [
{
"language" : "German",
"last_name" : {
"$exists" : true
}
},
{
"last_name" : "Cole"
}
]
},
"fields" : {
"first_name" : 1,
"gender" : 1,
"_id" : 0
},
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "production.customers",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : [
{
"language" : {
"$eq" : "German"
}
},
{
"last_name" : {
"$eq" : "Cole"
}
},
{
"last_name" : {
"$exists" : true
}
}
]
},
"collation" : {
"locale" : "de",
"caseLevel" : false,
"caseFirst" : "off",
"strength" : 3,
"numericOrdering" : false,
"alternate" : "non-ignorable",
"maxVariable" : "punct",
"normalization" : false,
"backwards" : false,
"version" : "57.1"
},
"winningPlan" : {
"stage" : "FETCH",
"filter" : {
"$and" : [
{
"last_name" : {
"$exists" : true
}
},
{
"language" : {
"$eq" : "German"
}
}
]
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"last_name" : 1,
"first_name" : 1
},
"indexName" : "german_name_index",
"collation" : {
"locale" : "de",
"caseLevel" : false,
"caseFirst" : "off",
"strength" : 3,
"numericOrdering" : false,
"alternate" : "non-ignorable",
"maxVariable" : "punct",
"normalization" : false,
"backwards" : false,
"version" : "57.1"
},
"isMultiKey" : false,
"multiKeyPaths" : {
"last_name" : [ ],
"first_name" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"last_name" : [
"[\"-E?1\u0001\b\u0001\u0007\", \"-E?1\u0001\b\u0001\u0007\"]"
],
"first_name" : [
"[MinKey, MaxKey]"
]
}
}
},
"rejectedPlans" : [ ]
}
}
},
{
"$project" : {
"language" : false,
"country" : false,
"salary" : false
}
},
{
"$sort" : {
"sortKey" : {
"first_name" : 1
}
}
},
{
"$project" : {
"_id" : false,
"gender" : true,
"first_name" : true
}
}
],
"ok" : 1
User-Defined Roles – Limiting Access to the Views
One of the reasons for creating the views was to protect some of the data (the customers’ salaries) as not all users should see this information. At this point, all users can still access the base “customers” collection and so we’ve fallen short of that objective. User-defined roles to the rescue!
We create an admin user that has the built in root role and so can access any database, create new users, and perform any other activity:
use admin
db.createUser({
user: "admin",
pwd: "secret",
roles: [
{role:"root",db:"admin"}
]
})
The next step is to create a role that only gives its members read access to the germanSpeakersRedacted collection (within the production database):
use admin
db.createRole(
{
role: "germanViewer",
privileges: [
{ resource: { db: "production", collection: "germanSpeakersRedacted" }, actions: [ "find" ] }
],
roles: []
}
)
You can then create one or more users that have germanViewer within their defined roles:
use admin
db.createUser({
user: "germanIT",
pwd: "secret",
roles: [
{role:"germanViewer",db:"admin"}
]
})
Additional privileges can be added to existing roles using grantPrivilegesToRole and extra roles can be assigned to existing users using grantRolesToUser.
For these access controls to work, users must be created with appropriate permissions and the MongoDB server process must be started with the --auth option:
mongod --auth
When connecting to the database as our newly-created admin user, the base customers collection is still accessible:
mongo -u admin -p secret --authenticationDatabase admin
use production
db.customers.findOne()
{
"_id" : ObjectId("57fb8fbb99b01440193088eb"),
"first_name" : "Ben",
"last_name" : "Dixon",
"country" : "Germany",
"avatar" : "https://robohash.org/quiseumquam.bmp?size=50x50&set=set1",
"ip_address" : "10.102.15.35",
"dependents" : [
{
"name" : "Ben",
"birthday" : "12-Apr-1994"
},
{
"name" : "Lucas",
"birthday" : "22-Jun-2016"
},
{
"name" : "Erik",
"birthday" : "05-Jul-2005"
}
],
"birthday" : "02-Jul-1964",
"salary" : "£910070.80",
"skills" : [
{
"skill" : "Cvent"
},
{
"skill" : "TKI"
}
],
"gender" : "Male",
"language" : "German"
}
When connecting as the germanIT user, only the German view can be accessed:
mongo -u germanIT -p secret --authenticationDatabase admin
use production
show collections
2016-10-28T10:24:03.765+0100 E QUERY [main] Error: listCollections failed: {
"ok" : 0,
"errmsg" : "not authorized on production to execute command { listCollections: 1.0, filter: {} }",
"code" : 13,
"codeName" : "Unauthorized"
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
DB.prototype._getCollectionInfosCommand@src/mongo/shell/db.js:805:1
DB.prototype.getCollectionInfos@src/mongo/shell/db.js:817:19
DB.prototype.getCollectionNames@src/mongo/shell/db.js:828:16
shellHelper.show@src/mongo/shell/utils.js:748:9
shellHelper@src/mongo/shell/utils.js:645:15
@(shellhelp2):1:1
db.customers.findOne()
2016-10-21T14:40:19.477+0100 E QUERY [main] Error: error: {
"ok" : 0,
"errmsg" : "not authorized on production to execute command { find: \"customers\", filter: {}, limit: 1.0, singleBatch: true }",
"code" : 13,
"codeName" : "Unauthorized"
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
DBCommandCursor@src/mongo/shell/query.js:702:1
DBQuery.prototype._exec@src/mongo/shell/query.js:117:28
DBQuery.prototype.hasNext@src/mongo/shell/query.js:288:5
DBCollection.prototype.findOne@src/mongo/shell/collection.js:294:10
@(shell):1:1
db.germanSpeakersRedacted.findOne()
{
"_id" : ObjectId("57fb8fbb99b01440193088eb"),
"first_name" : "Ben",
"last_name" : "Dixon",
"avatar" : "https://robohash.org/quiseumquam.bmp?size=50x50&set=set1",
"ip_address" : "10.102.15.35",
"dependents" : [
{
"name" : "Ben",
"birthday" : "12-Apr-1994"
},
{
"name" : "Lucas",
"birthday" : "22-Jun-2016"
},
{
"name" : "Erik",
"birthday" : "05-Jul-2005"
}
],
"birthday" : "02-Jul-1964",
"skills" : [
{
"skill" : "Cvent"
},
{
"skill" : "TKI"
}
],
"gender" : "Male"
}
MongoDB Compass – Viewing Views Graphically
While the mongo shell is very powerful and flexible, it is often easier to understand and navigate your data graphically, this is where MongoDB Compass is invaluable. The good news is that MongoDB Compass handles views in exactly the same way as it does collections.
In Figure 1, we can view the documents in the base, customers, collection. Note that the salary value is visible.
Figure 1: View data in base customers collection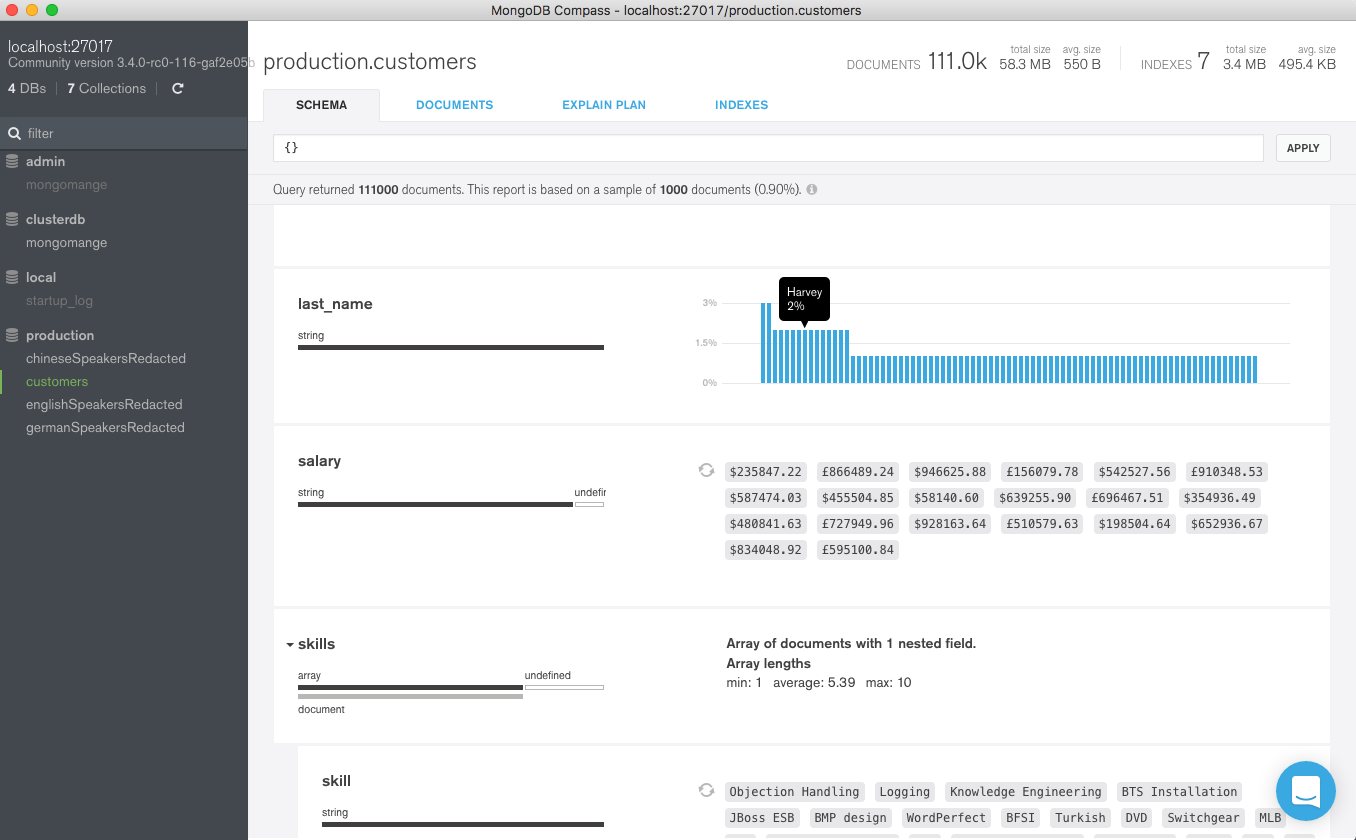
Figure 2 confirms that the salary field has been removed from the German view.

Figure 2: Salary has been redacted from the German view
In Figure 3, we see that only Chinese documents have been included in the Chinese view.
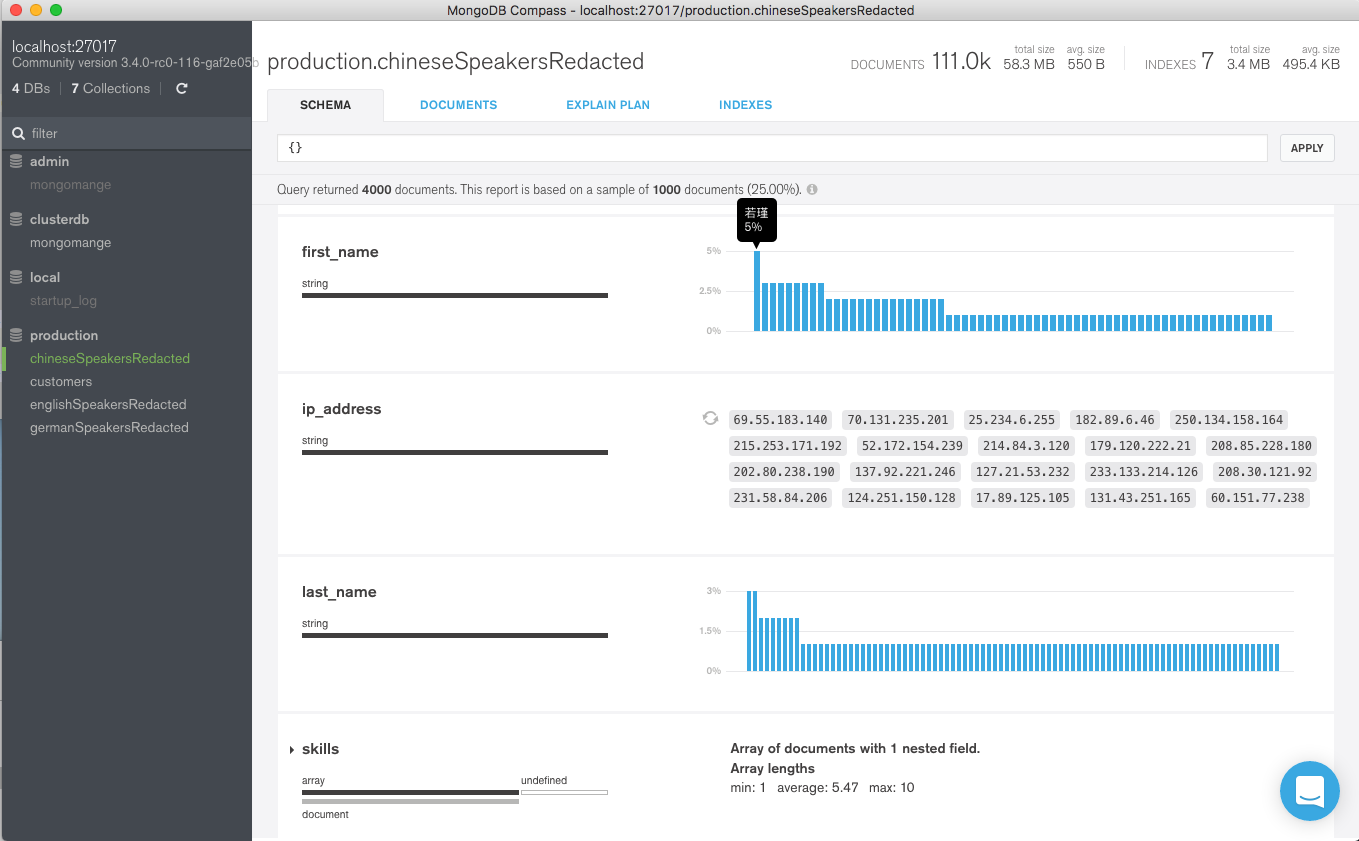
Figure 3: Chinese view contains only Chinese documents
Next Steps
Collation and read-only views are just 2 of the exciting new features added in MongoDB 3.4 – read more and these and everything else that’s new in MongoDB 3.4: What’s New.