Fig. 1 MySQL per-row replication filtering
A MySQL Software preview is available which allows you to write Lua scripts to control replication on a statement-by-statement basis. Note that this is prototype functionality and is not supported but feedback on its usefulness would be gratefully received.The final version would allow much greater functionality but this preview allows you to implement filters on either the master or slave to examine the statements being replicated and decide whether to continue processing each one or not.
After reading this article, you may be interested in trying this out for yourself and want to create your own script(s). You can get more information on the functionality and download the special version of MySQL from http://forge.mysql.com/wiki/ReplicationFeatures/ScriptableReplication
To understand how this feature works, you first need to understand the very basics about how MySQL replication works. Changes that are made to the ‘Master’ MySQL Server are written to a binary log. Any slave MySQL Servers that subscribe to this master are sent the data from the master’s binary log; the slave(s) then copy this data to their own relay log(s). The slave(s) will then work through all of the updates in their relay logs and apply them to their local database(s). The implementation is a little more complex when using MySQL Cluster as the master’s updates may come through multiple MySQL Servers or directly from an application through the NDB API but all of the changes will still make it into the binary log.
MySQL Replication supports both statement and row based replication (as well as mixed) but this software preview is restricted to statement based replication. As MySQL Cluster must use row based replication this preview cannot be used with Cluster but the final implementation should work with all storage engines.
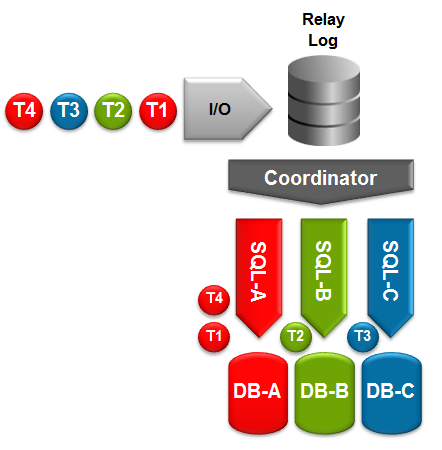
As show in Fig. 1 there are 4 points where you can choose to filter statements being replicated:
- Before the update is written to the binary log
- After the update has been read from the binary log
- Before the update is written to the relay log
- After the update has been read from the relay log
The final 2 interest me most as it allows us to have multiple slaves which apply different filters – this article includes a worked example of how that could be exploited.

Fig. 2 Details for each filtering point
The filters are written as Lua scripts. The names of the script file, module name and function names vary depending on which of these filtering points is to be used. Fig. 2 shows these differences. In all cases, the scripts are stored in the following folder: “<mysql-base-directory>/ext/replication”.
This article creates 2 different scripts – one for each of 2 slave servers. In both cases the filter script is executed after an update is read from the relay log. One slave will discard any statement of the form “REPLACE INTO <table-name> SET sub_id = 401, …” by searching for the sub string “sub_id = X” where X is even while the second slave will discard any where X is odd. Any statement that doesn’t include this pattern will be allowed through.

Fig. 3 Implementation of odd/even sharded replication
If a script returns TRUE then the statement is discarded, if it returns FALSE then the replication process continues. Fig. 3 shows the architecture and pseudo code for the odd/even replication sharding.
The actual code for the two slaves is included here:
slave-odd: <mysql-base-directory>/ext/replication/relay_log.lua
function after_read(event)
local m = event.query
if m then
id = string.match(m, "sub_id = (%d+)")
if id then
if id %2 == 0 then
return true
else
return false
end
else
id = string.match(m, "sub_id=(%d+)")
if id then
if id %2 == 0 then
return true
else
return false
end
else
return false
end
end
else
return false
end
end
slave-even: <mysql-base-directory>/ext/replication/relay_log.lua
function after_read(event)
local m = event.query
if m then
id = string.match(m, "sub_id = (%d+)")
if id then
if id %2 == 1 then
return true
else
return false
end
else
id = string.match(m, "sub_id=(%d+)")
if id then
if id %2 == 1 then
return true
else
return false
end
else
return false
end
end
else
return false
end
end
Replication can then be set-up as normal as described in Setting up MySQL Asynchronous Replication for High Availability with the exception that we use 2 slaves rather than 1.
Once replication has been started on both of the slaves, the database and tables should be created; note that for some reason, the creation of the tables isn’t replicated to the slaves when using this preview load and so the tables actually need to be created 3 times:
mysql-master> CREATE DATABASE clusterdb; mysql-master> USE clusterdb; mysql-master> CREATE TABLE sys1 (code INT NOT NULL PRIMARY KEY, country VARCHAR (30)) engine=innodb; mysql-master> CREATE TABLE subs1 (sub_id INT NOT NULL PRIMARY KEY, code INT) engine=innodb;
mysql-slave-odd> USE clusterdb; mysql-slave-odd> CREATE TABLE sys1 (code INT NOT NULL PRIMARY KEY, country VARCHAR (30)) engine=innodb; mysql-slave-odd> create table subs1 (sub_id INT NOT NULL PRIMARY KEY, code INT) engine=innodb;
mysql-slave-even> USE clusterdb; mysql-slave-even> CREATE TABLE sys1 (code INT NOT NULL PRIMARY KEY, country VARCHAR (30)) engine=innodb; mysql-slave-even> CREATE TABLE subs1 (sub_id INT NOT NULL PRIMARY KEY, code INT) engine=innodb;
The data can then be added to the master and then the 2 slaves can be checked to validate that it behaved as expected:
mysql-master> REPLACE INTO sys1 SET area_code=33, country="France";
mysql-master> REPLACE INTO sys1 SET area_code=44, country="UK";
mysql-master> REPLACE INTO subs1 SET sub_id=401, code=44;
mysql-master> REPLACE INTO subs1 SET sub_id=402, code=33;
mysql-master> REPLACE INTO subs1 SET sub_id=976, code=33;
mysql-master> REPLACE INTO subs1 SET sub_id=981, code=44;
mysql-slave-odd> SELECT * FROM sys1;
+------+---------+
| code | country |
+------+---------+
| 33 | France |
| 44 | UK |
+------+---------+
mysql-slave-odd> SELECT * FROM subs1;
+--------+------+
| sub_id | code |
+--------+------+
| 401 | 44 |
| 981 | 44 |
+--------+------+

Fig. 4 Results of partitioned replication
mysql-slave-even> SELECT * FROM sys1;
+------+---------+
| code | country |
+------+---------+
| 33 | France |
| 44 | UK |
+------+---------+
mysql-slave-even> SELECT * FROM subs1;
+--------+------+
| sub_id | code |
+--------+------+
| 402 | 33 |
| 976 | 33 |
+--------+------+
Fig. 4 illustrates this splitting of data between the 2 slaves – all rows from the system table are stored in both databases (as well as in the master) while the data in the subscriber table (and it would work for multiple subscriber tables too) are partitioned between the 2 databases – odd values in one, even in the other. Obviously, this could be extended to more slaves by changing the checks in the scripts.
As an illustration of how this example could be useful, all administrative data could be provisioned into and maintained by the master – both system and subscriber data. Each slave could then serve a subset of the subscribers, providing read-access to the administrative data andread/write access for the more volatile subscriber data (which is mastered on the ‘slave’). In this way, there can be a central point to manage the administrative data while being able to scale out to multiple, databases to provide maximum capacity and performance to the applications. For example, in a telco environment, you may filter rows by comparing a subscriber’s phone number to a set of area codes so that the local subscribers are accessed from the local database – minimising latency.
From a data integrity perspective, this approach is safe if (and only if) the partitioning rules ensures that all related rows are on the same slave (in our example, all rows from all tables for a particular subscriber will be on the same slave – so as long as we don’t need transactional consistency between different subscribers then this should be safe).

Fig. 5 Partitioned replication for MySQL Cluster
As mentioned previously this software preview doesn’t work with MySQL Cluster but looking forward to when it does, the example could be extended by having each of the slave servers be part of the same Cluster. In this case, the partitioned data will be consolidated back into a single database (for this scenario, you would likely configure just one server to act as the slave for the system data). On the face of it, this would be a futile exercise but in cases where the performance bottlenecks on the throughput of a single slave server, this might be a way to horizontally scale the replication performance for applications which make massive numbers of database writes.